A selection of our clients









The firm's data ecosystem, in one intelligent engine.
Integrate all internal and external data sources into a living, learning context engine built to optimize dealmaking and drive sustained competitive advantage for your firm.
.svg)


Helping tech leadership get data in the fast lane
This purpose-built data engine pulls together your entire market and proprietary data ecosystem, enabling Frontier LLMs to surface the best opportunities for your business. Connected and embedded within your existing tech stack in 6 weeks.

Deal teams: From origination to value creation
Empower sourcing teams with automated specific target opportunities, market monitoring insights to reach out, and at-a-glance company reports or pre-meeting briefs to ensure you're prepared throughout the deal cycle.
Connecting the unconnected in dealmaking
Unifying the data, intelligence, and signals that exist for private markets firms, and transforming it into deals.
Finally, a platform your firm can truly customize
Deal Engine is offered as a white-labelled solution, resulting in faster onboarding, adoption, brand alignment and organizational buy-in.
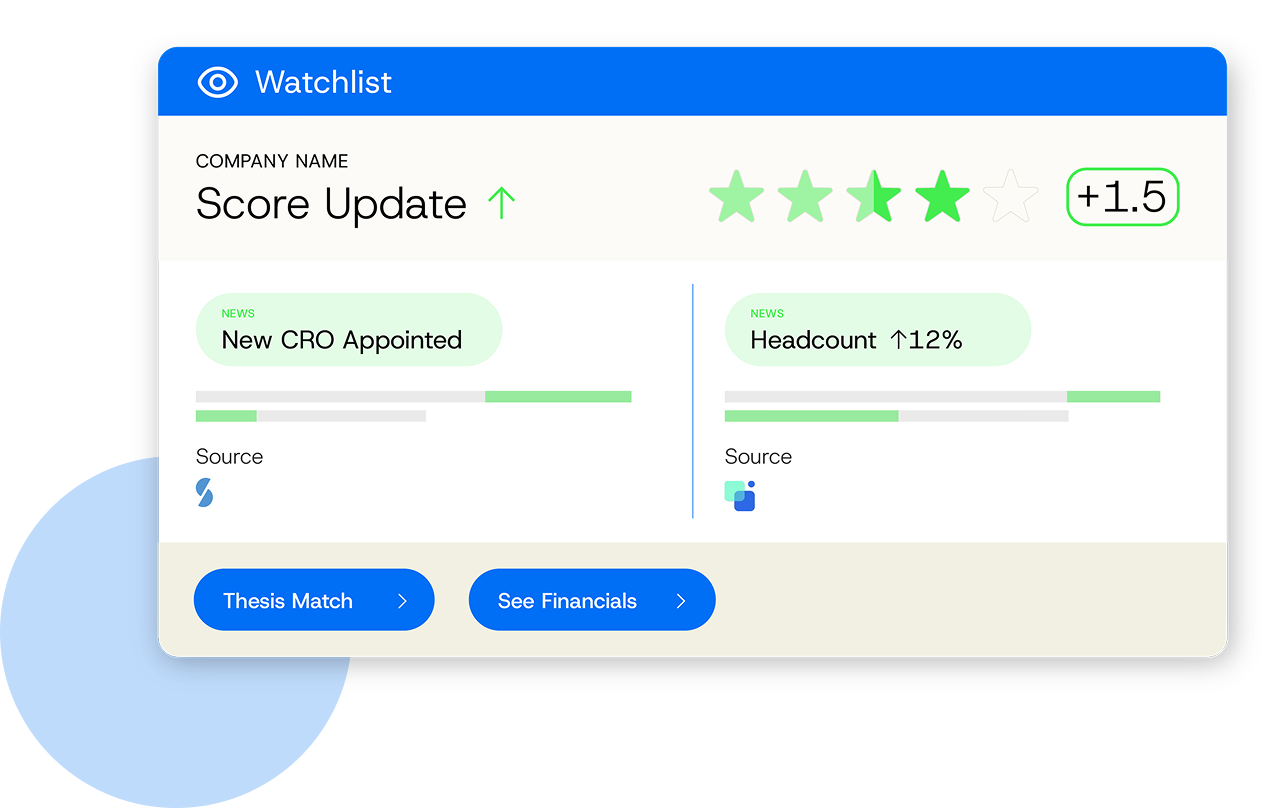
Find more net new deals for your firm
Codify your strategy, track the market and increase relevance. Deal Engine delivers always-on agentic AI intelligence that continuously monitors your entire investable universe — specified by your thesis — and surfaces high-fit targets.
Unify data, unlock insights
White-label the technology and make your Deal Engine entirely yours. Deal Engine brings together proprietary, third-party, and public data into a single connected layer, transforming information into actionable intelligence.

Power up instead of piling on
Optimize your data spend and unlock the value in your CRM and internal documents. Deal Engine enriches your CRM with structured, intelligent data without adding clutter, complimenting your existing tech stack instead of complicating it.
Build the gen AI-enabled firm of tomorrow
Fuel your AI roadmap with an integrated agentic AI intelligence layer. Accumulate and train your firm’s own proprietary dealmaking engine, built to evolve with your strategy and scale firm-wide tech-readiness.

Three questions investment banks should ask about their data
Investment banking teams are experimenting with AI in growing numbers. The use cases are well understood: faster research, better meeting preparation, more efficient deal documentation. But a pattern keeps emerging. Tools that perform well in a demo produce unreliable output in practice, and the reason is almost always the same. The data underneath them was not ready.
CEO Phil's interview with FinTecBuzz: “Data architecture is the real AI investment”
Read the full article on FinTecBuzz: FinTech Interview with Phil Westcott, Founder and CEO of Deal Engine There's no shortage of PE firms experimenting with Frontier AI like Claude. But talk to most Managing Partners about what's actually working, and you'll hear the same frustration: fragmented efforts, high token consumption, and AI that produces confident output from incomplete information.
What good AI adoption actually looks like in private markets firms
Alex Bajdechi, VP of Sales, Deal Engine
What's new in Deal Engine: Q1 2026 product update
Chas Frederick, Product Manager, Deal Engine